
The idea isn’t new
People have been building second brains forever. Zettelkasten, GTD, Notion wikis, Roam Research rabbit holes. Entire businesses exist around personal knowledge management. AI didn’t invent the concept. It just made everyone talk about it again.
Nate B Jones made a video about building a second brain that stuck with me. His system is different from mine, but his core point landed: self-curated systems usually fail. You start strong, then life gets busy, and the system goes stale. The best second brain is one that maintains itself.
Why I needed one
I didn’t set out to build a second brain. I just had a problem.
Too much data sitting in too many sessions. I use Claude across four or five surfaces: Claude Code in the terminal, Claude Desktop, claude.ai in the browser, Claude on my phone. Each one starts fresh. CLAUDE.md files help with project context, and Claude Code has a built-in memory feature, but both are local. My phone doesn’t know what my laptop learned last week.
And none of it works outside Claude’s ecosystem. I also use Gemini. I wanted one memory that works everywhere, regardless of which model I’m talking to.
So I built one
I built a remote MCP server called Universal Memory. It runs on Cloudflare Workers and stores a knowledge graph based on Anthropic’s own primitive: entities, observations, and relations.

Entities are the nodes. People, companies, projects, concepts. Think of them as index cards with a name and a type.
Observations are facts attached to entities. “Acme Corp has 12 employees.” “The project deadline is March 30.” “Sarah’s phone number is 801-555-1234.” One fact per observation, atomic and searchable.
Relations are the edges. “Jason → works_at → Company X.” “Project Y → uses → Tool Z.” Directed, typed, connecting entities to each other.
The server is dumb. It stores data, retrieves data, and searches. It doesn’t interpret anything. The LLM decides what’s worth remembering. You tell it to remember something, semantically, in plain language, and it figures out where that goes in the graph and what new relationships it implies. You don’t manage the structure. You just talk.
Claude Code built most of it
This is another project where Claude Code did most of the coding. I directed, reviewed, glanced at diffs. The server is written in TypeScript, which isn’t my favorite language. Didn’t matter. Claude handled it just fine.
The stack is entirely Cloudflare: Workers for compute, D1 (SQLite) for storage, Vectorize for vector search, Workers AI for generating embeddings. All serverless. No containers, no database to manage.
The primitive is flexible
This is the part that surprised me. The entity/observation/relation structure handles almost anything.
A to-do item? That’s an observation on a project entity. A phone number? Observation on a person. A meeting note? Observations on a person with a relation to a project. A book recommendation? Entity for the book, observation for who recommended it, relation to the recommender.
You don’t need separate apps for separate things. One structure, one place, one search. And as Nate B Jones points out in a more recent video, you can build UIs for any of these on top of the data if you want to go beyond text.
The cold start problem
An empty second brain is useless. You open it, it knows nothing, and you close it. The cold start problem kills most personal knowledge systems before they get useful.
I solved this by pointing it at a year of my Gmail, recent WhatsApp chats, and a few weeks of journal entries. Gmail has its own remote MCP server, so the wiring was easy. A cron job fetches recent threads, skips promotions and junk, and sends each conversation to Claude for extraction. Claude pulls out the entities, observations, and relations and writes them to the graph automatically.
One pass and the graph had dozens of people, companies, and projects. It knew who I’d been talking to, what about, and how they were connected. Instant context. No manual curation.
It works everywhere
Most MCP servers run locally. They’re a process on your machine that your AI client talks to over stdio. That means they only work on that machine, with that client. Useful, but limited.
A remote MCP server runs in the cloud. It exposes tools over HTTPS. Any MCP-compatible client can connect to it from anywhere, just by pointing at a URL. No install, no local process, no per-machine setup.

That’s what makes Universal Memory cross-ecosystem. It connects to Claude Code, Claude Desktop, claude.ai, and Claude on iOS, but also ChatGPT, Gemini, Cursor, VS Code Copilot, Windsurf, and JetBrains. Same memory, every device, every model.
I jot something down from my phone. I retrieve it from my laptop. I ask about a contact while I’m out and it pulls up everything it knows. The architecture doesn’t care which LLM is calling it.
How search works
When an LLM searches my memory, two things happen in parallel.
Semantic search embeds the query into a vector and finds observations with similar meaning. If I search “that startup with 12 people,” it finds Acme Corp even though I never stored those exact words. It matches on meaning.
Keyword search runs a full-text search on the same observations. If I search “Acme Corp,” it finds the exact match instantly.
Both results get merged and deduplicated. You need both. Semantic alone misses exact names. Keyword alone misses conceptual connections.
The visualization
The server has a /viz endpoint that renders the entire graph as a D3 force-directed network.
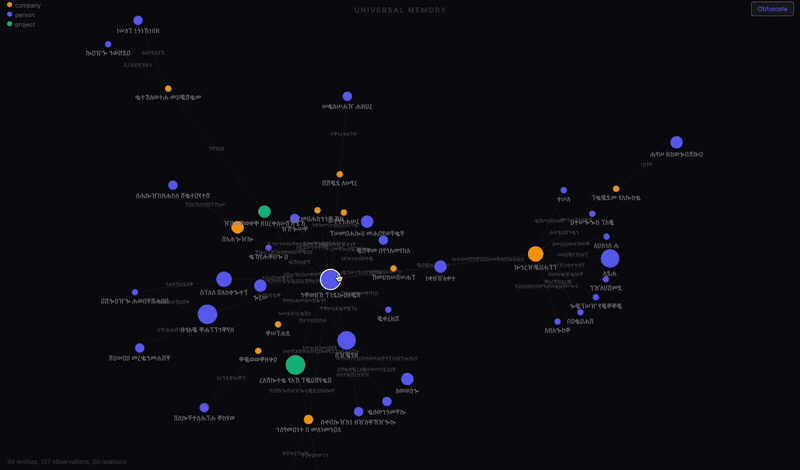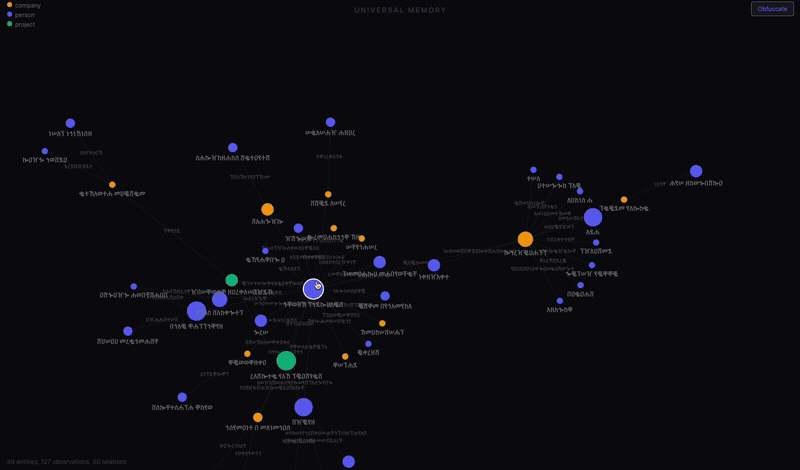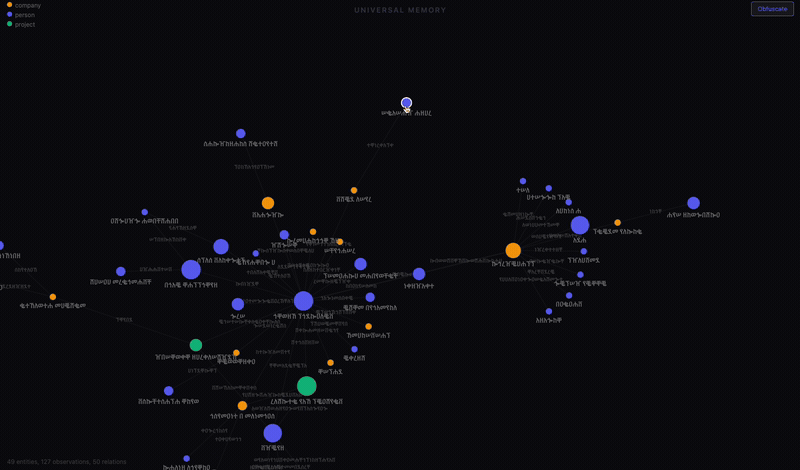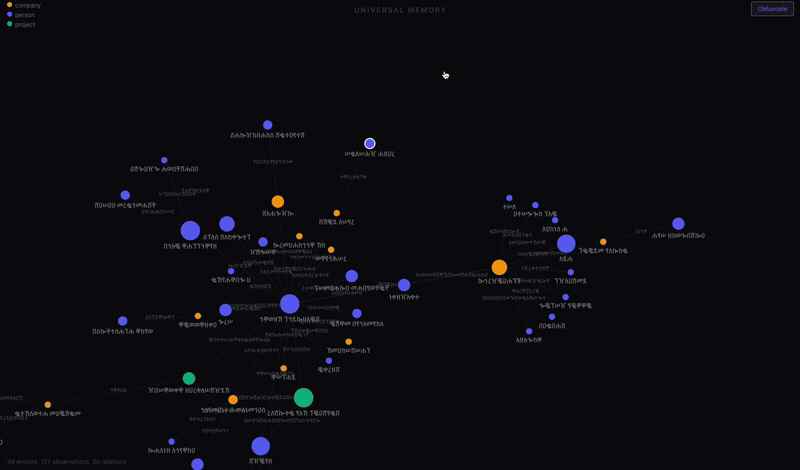
Nodes are sized by how many observations they have and colored by type: blue for people, green for companies, orange for projects. Click a node and a sidebar shows every fact and relation attached to it. You can drag nodes around, zoom and pan, and explore the shape of what your AI actually knows about your life.
I built an obfuscate mode that scrambles all the text for screenshots. That’s what you see above. The structure is real. The labels are not.
Fork it or build your own
The repo is open source: github.com/JasonMakes801/universal-memory-mcp. Fork it, deploy to Cloudflare, and you’re up. Or build your own from scratch as a learning exercise.
The stack is all Cloudflare: Workers, D1, Vectorize, Workers AI. You can get started on the free tier. If you outgrow it, the paid plan is $5/month. The entity/observation/relation primitive is simple enough to implement in a weekend, especially if you let Claude Code do the typing.
The graph grows on its own now. I’m running Claude loops: new Gmail threads processed daily, new journal entries weekly. I’ll add more sources over time.
At some point the graph gets big enough that search alone won’t cut it and I’ll need some kind of index layer on top. I’ll find out.