In my last post, I wrote about the unreasonable effectiveness of model stacking for media search—combining CLIP, Whisper, and ArcFace to find video content through visual descriptions, dialog, and faces. Over the holidays I expanded that afternoon hack into something more production-like.
Live demo: fennec.jasongpeterson.com Starter code: github.com/JasonMakes801/fennec-search
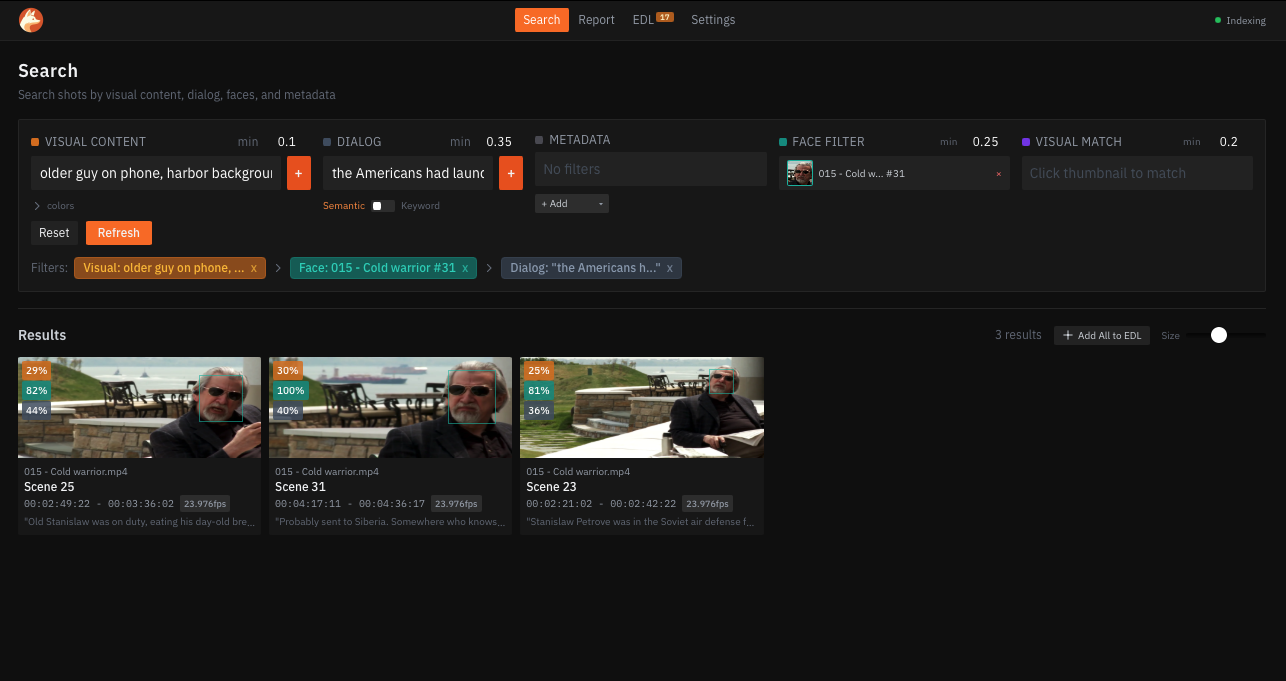
Try This
- Go to fennec.jasongpeterson.com (desktop browser)
- Enter
older man on phone, harbor backgroundin Visual Content → click + - Click the face of the older guy with glasses sitting with the harbor at his back
- Enter
the Americans had launched their missilesin Dialog (Semantic mode) → click + - Play the clip
You’ve drilled down to an exact shot without metadata, timecodes, or remembering exact words. The semantic search is fuzzy—he actually says “What it was telling him was that the US had launched their ICBMs,” but that’s close enough.
What’s Under the Hood
- Containerized architecture: Vue/Nginx frontend, FastAPI backend, standalone ingest worker, Postgres+pgvector—all via docker-compose
- Background enrichment: Polling-based worker that handles drive mounting/unmounting gracefully (Watchdog doesn’t work reliably with NFS/network shares)
- Semantic dialog search: Sentence-transformer embeddings so “Americans launched missiles” finds “US fired rockets”
- Frame-accurate playback: HTML5 video decode to canvas using
requestVideoFrameCallback() - EDL export: Queue scenes and export CMX 3600 for NLE roundtrip
The Postgres + pgvector setup turned out cleaner than expected—vector similarity combined with metadata filtering in a single query just works.
Links
Demo footage from Pioneer One, a Creative Commons-licensed Canadian drama. Built with significant help from Claude Code.